Раджа Кодури продемонстрировал процессоры Xe
Раджа Кодури, глава компании Intel, представил фотографии с новыми графическими процессорами Xe, продемонстрировав анонсированный ранее плиточный дизайн.
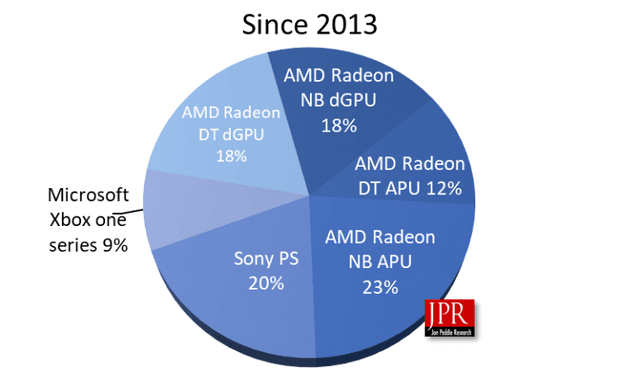
Архитектура Xe изначально создавалась масштабируемой для использования в центрах обработки данных, и теперь стало понятно, как это «плиточное» масштабирование выглядит.

На представленных изображениях показаны три варианта ускорителей, на одну плитку, две и четыре. Последний назван BFP (big 'fabulous' package).
Ранее сообщалось, что эта мультичиповая масштабируемая система построена как чиплет. За счёт масштабирования она позволит получить ту же гибкость, что предлагают мультичиповые процессоры AMD EPYC. При этом такая конструкция может не коснуться рынка потребительских видеокарт, поскольку они требовательны ко времени задержек, а именно этот параметр и является слабым местом конструкций MCM.